


Section: New Results
Interaction Design
Question Answering over Linked Data
Participant : Elena Cabrio.
While an increasing amount of semantic data is being published on the Web, the crucial issue of how typical Web users can access this body of knowledge comes to light. This PostDoc project focuses on the development of methods for a flexible mapping between questions in natural language, and data objects. The main purpose is to allow an end user to submit a query to an RDF triple store in English and get results in the same language, masking the complexity of SPARQL expressions and RDFS/OWL inferences involved in the resolution, but at the same time profiting from the expressive power of these standards. In particular, we address the problem of automatic identification of the relevant relations in Question Answering (QA), to capture the context in which the requests should be interpreted, to be able to determine the constraints on the database query.
We aim at investigating the applicability of the Textual Entailment (http://aclweb.org/aclwiki/index.php?title=Textual_Entailment_Portal ) (TE) approach, recently proposed as a general framework for applied semantics, where linguistic objects are mapped by means of semantic inferences at a textual level [55] . According to such framework, entailment relations can be detected between an input question and a set of relational patterns that represent possible lexicalizations of the relations of interest. Such relations, collected in a pattern repository, can be associated to a SPARQL query to the database. A TE system should therefore first try to establish an entailment relation between an input question and each of the relations in the pattern repository. Then, the SPARQL queries associated to the relations for which the entailed patterns have been found are composed in a single query to the database.
Since this PostDoc research work has just started, our early efforts were directed toward the study of the state of the art on QA over Linked Data. We are currently carrying out a feasibility study on the extraction of the relational patterns from Wikipedia (as the source of free text) and the use of DBpedia (http://dbpedia.org ) as a linked data resource. For the experimental part, we are considering energy and environment as the reference scenario.
Mobile Access to the Web of Data
Participants : Luca Costabello, Fabien Gandon.
This thesis, directed by F. Gandon and I. Herman (CWI and Semantic Web Activity Lead at W3C) deals with accessing the Web of Data from mobile environments. The first year addressed the multi-faceted relationship between ubiquitous consumption of Linked Data and mobile context. More specifically, focus has been put on RDF adaptive representation and on context-aware SPARQL endpoints access control.
When accessed from devices immersed into ubiquitous environments, RDF resources must be properly adapted to the mobile context in which the consumption is performed. A domain-independent, lightweight vocabulary for displaying Web of Data resources in mobile environments has been designed (PRISSMA, Presentation of Resources for Interoperable Semantic and Shareable Mobile Adaptability [36] ). The vocabulary is the first step towards an adaptive rendering engine for RDF data coupled with a declarative framework to share and re-use presentation information for context-adaptable user interfaces for Linked Data.
Another line of research regards the role of mobile context in restricting access to the Web of Data. Ubiquitous connectivity enables new scenarios in consuming Linked Data and access control in such pervasive environments must not ignore the mobile context in which RDF consumption takes place, as uncontrolled access in given situations may be undesired by data providers. The work led to enhance the access control framework for SPARQL endpoints proposed by teammate Serena Villata (see 6.2.3 ) with the notion of mobile context provided by PRISSMA.
Access Control for the Web of Data
Participant : Serena Villata.
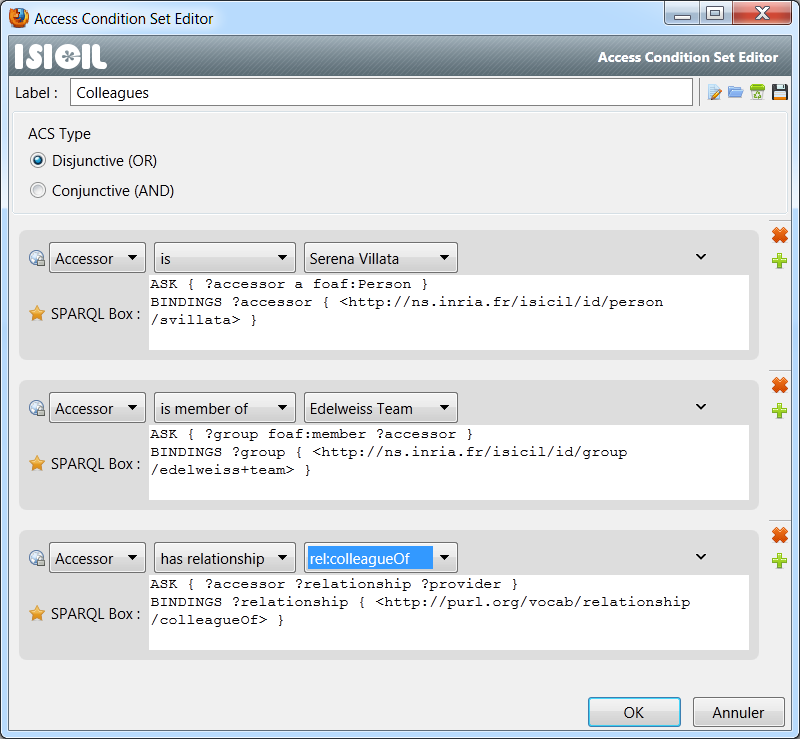
This research activity is mainly focussed on the field of Knowledge Representation. First, we have proposed a new access control model for the Web of Data and the Social Web. In particular, we have introduced the S4AC ontology (http://ns.inria.fr/s4ac/ ) where the meaning of the access policies and their components is defined. This access control model proposes, also, a contextual evaluation of the accessors' information. This model has been applied both to the world of Linked Data and to the world of social networks. This research activity has been addressed in the context of the DataLift ANR project [21] , [20] .
Second, we have continued a research activity in the area of argumentation theory. In this context, we are exploring the use of argumentation theory for modeling trust in those systems which deal with incomplete knowledge, and for providing explanations about the agents' choices [22] , [19] , [23] , [25] .
ISICIL
Participants : Nicolas Delaforge, Fabien Gandon.
As the leading team of the ISICIL project, we have developed many software components (client-side and server-side) to enrich the ISICIL platform. First, the whole server mechanism was redesigned, in order to improve the server performance, to strengthen and modularize the framework as well. Many semantic REST services were added (activity stream, syndication, subscription/notification, graphs and charts visualizations).
In collaboration with Erwan Demairy, in charge of the SegViz ADT, a Gephi-ISICIL connector was implemented, allowing ISICIL users to visualize the results of their SPARQL queries directly into a dynamic graph. A demo of this work was presented during the ISICIL public seminarium in September. Furthermore, projects such as Datalift and ISICIL had brought out the need of an access control model for the Web of Data. For this purpose, we designed the S4AC model and ontology and we realized a prototype to evaluate it based on the ISICIL dataset Figure 4 .
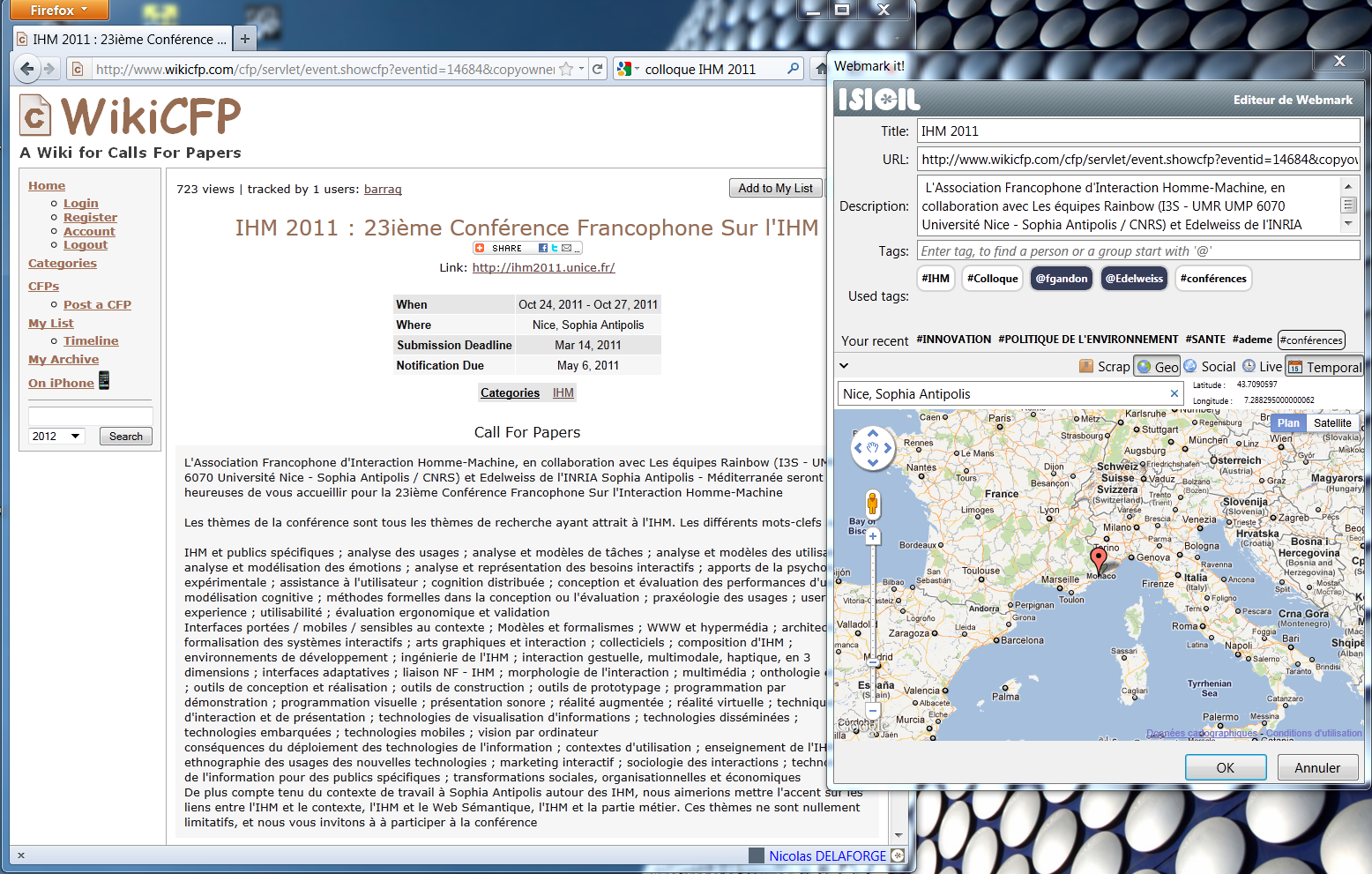
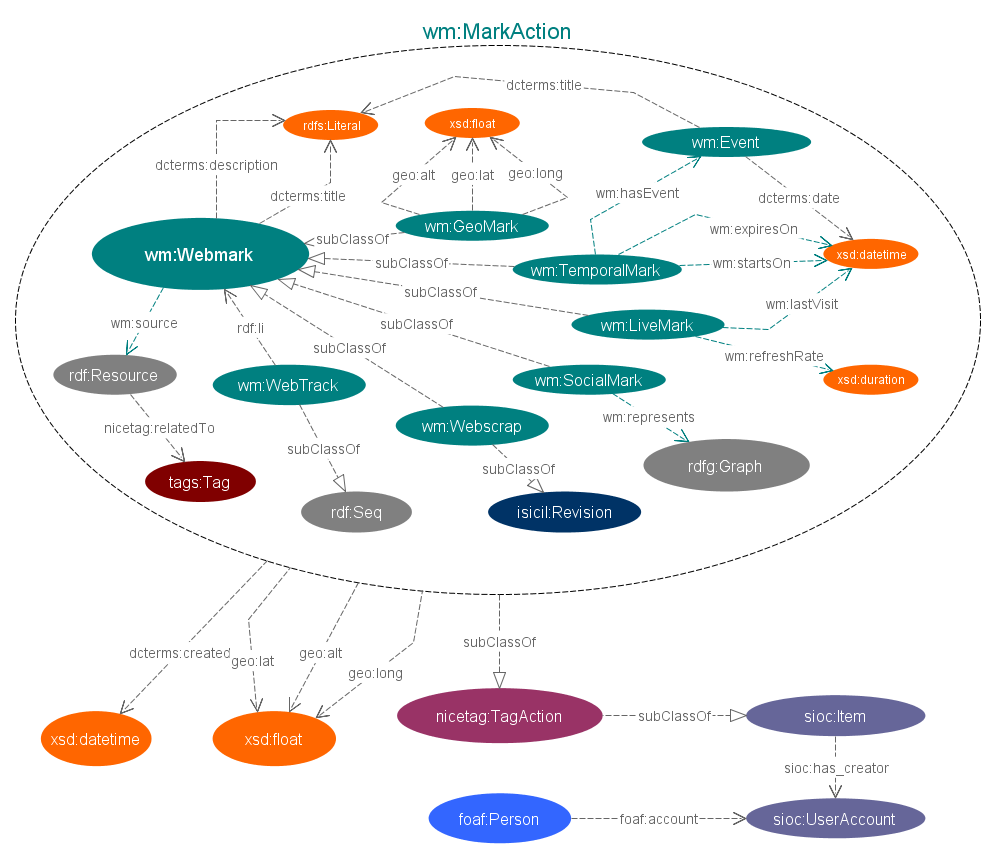
Since the Philoweb conference in 2010, a workshop dedicated to philosophical engineering was attached to the french IC conference in Chambery. We presented there the advancement of a brand new bookmark model called Webmarks which semantically models the user interest on a web resource (Figure 5 & 6 ). A long paper on this work was accepted in the EGC 2012 conference and will be published in the RNTI journal (Hermann editions) [27] .
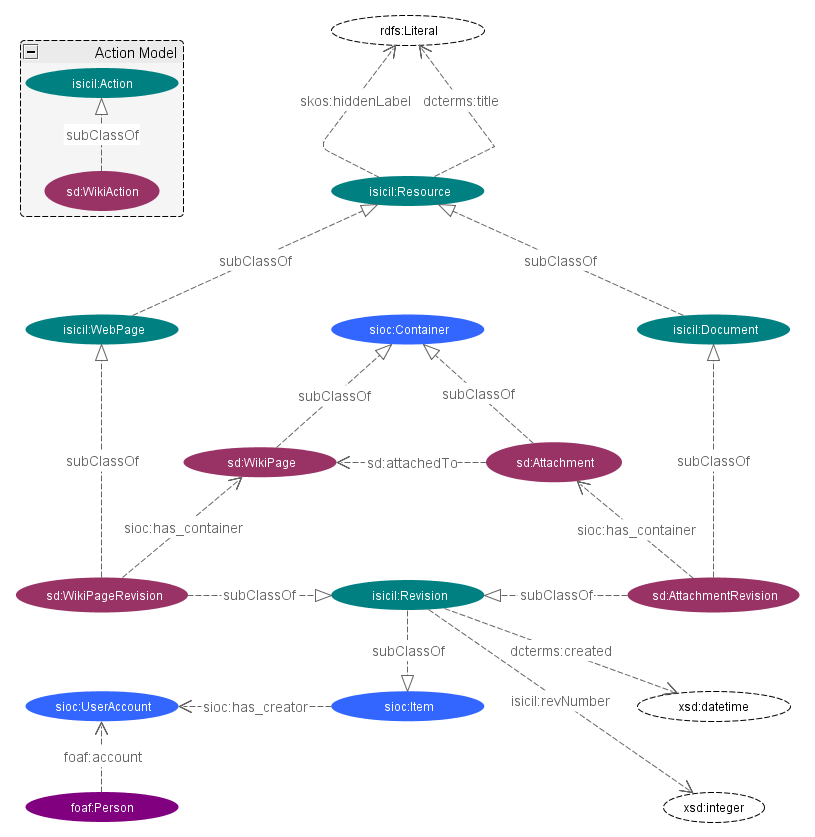
We also collaborate with the I3S team in a task of semantization of a commercial wiki, called Mindtouch. This wiki is enhanced with semantic description of its content (Figure 7 ), its users are part of the ISICIL social network and their activities on the wiki are reported on the metadata server. This tool represents the editorial layer of the software bundle developed to improve the business intelligence tasks. This work was also accepted as a long paper in the EGC 2012 conference [26] .
Models and Methods for Representing and Identifying Groups of Individuals and Their Activities
Models and Methods for Representing and Identifying "Collective Personas"
Participant : Alain Giboin.
Context of the work: ISICIL project.
As opposed to Individual Personas (which are user models represented as specific, realistic humans), Collective personas are models representing specific, realistic groups of people as such (e.g., teams, communities). Collective personas are aimed to design groupware more closely adapted to groups. In 2010, we updated our review of the existing methods for elaborating collective personas. This year, we published the updated review [17] .
Models and methods for Representing and Identifying Relationships between Individuals
Participants : Alain Giboin, Neji Bouchiba.
Context of the work: AVISICIL project, in collaboration with researchers from the Kewi team (I3S, UNS) and from the Laboratoire de Psychologie Cognitive et Sociale (UNS) who are involved in affective computing design projects (designing systems intended to help elderly people maintain their relationships, or autistic children to build relationships with others).
Digital technologies have been claimed to contribute to prevent elderly people from social isolation or loss of social ties. For example, ubiquitous computing, online social networking and affective computing have been reported to facilitate social interaction [64] or to enhance social connectedness [61] among the elderly. Participating to a project aimed to design a system for recognizing, through various sensors, the affective states (emotions) that indicate a loss or maintenance of social ties, we conducted a social ergonomic study to provide elements of design and evaluation of such a system. Noting that depressive states are among the most significant signs of an actual or potential loss of social ties (see, e.g., [65] ), we focused the study in particular on: (a) the models describing the depressive states and the process of their recognition, and the links between these states and the state of social ties; (b) the sensors that can contribute to this recognition. In order to evaluate our solution (so-called GeREmo) with the elderly, we also identified, from an analysis of existing studies on the acceptability of digital technologies, criteria for assessing the acceptability of the GeREmo solution [50] .
Comparing and Bridging Models of Shared Representations and Representation Sharing Processes
Participant : Alain Giboin.
Context of the work: GDR CNRS Psycho Ergo, Groupe thématique Coopération homme-homme et Coopération homme-machine. Action de recherche RefCom (Réferentiel commun), co-leaded with Pascal Salembier (UTT).
Sharing representations or shared representations are often claimed to be a key factor for a collaboration to succeed. The notions of shared representations and representation sharing processes are examined in the research literature from several points of view; this variety of viewpoints gave rise to different conceptualizations, which are referred to using such terms as Common Frame of Reference, Mutual Intelligibility, Shared Context, Team/Situation Awareness, etc. In 2010, in order to achieve mutual intelligibility between researchers working on such conceptualizations, we elaborated and asked participants to the RefCom joint research action to test and to apply a grid for collaboratively comparing and bridging the conceptualizations (see Edelweiss activity report 2010 (http://raweb.inria.fr/rapportsactivite/RA2010/edelweiss/ )). This year, we analyzed and reported the results of the test and application of the grid [39] . This resulted in a revision of the grid.
Frameworks for taking pragmatic dimensions of ontologies into account
Participant : Alain Giboin.
Context of the work: Follow-up to the Palette European project. This work was done in collaboration with the Centre de Recherche sur l'Instrumentation, la Formation et l'Apprentissage, ULg (Belgium).
When designing ontologies, ontologists (i.e., knowledge engineers specialized in ontology engineering) most often focus on the semantic dimensions of ontologies (such as expressiveness, level of granularity, etc.). Pragmatic dimensions, i.e. dimensions related to the context of use (including the purpose) of the ontologies, are often neglected whereas they are critical to users: ontologies indeed are used in context. In brief, pragmatic dimensions are not taken seriously into account when engineering ontologies but they have to.
We developed a framework to analyze the way we attempted, in the context of the Palette EU project, to contextualize the ontologies underlying a set of semantic knowledge services dedicated to communities of practice. The framework was derived from the Ontology Framework elaborated by members of the Ontology Engineering community during the Ontology Summit 2007 [62] . Both frameworks define a series of "pragmatic dimensions" of ontologies. Because our derived framework did not cover all possible dimensions, we complemented it, by relying on existing work from the Ontology Engineering community in general, and from the Pragmatic Web community in particular [16] .
Explanation of Semantic Web Query Results
Participants : Rakebul Hasan, Fabien Gandon, Olivier Corby.
This PhD thesis, directed by Fabien Gandon and Olivier Corby, aims at opening the query-solving mechanism to the users, and handling and explaining the distribution of a query over several sources on the Semantic Web. This work is part of the Kolflow ANR project.
The current Semantic Web search engines are not able to explain how a given query result is obtained or why it has failed to obtain a result. The goal of opening the query-solving mechanism is to enable the Semantic Web query engines to explain the query solving process taking into account the inferences used to obtain the results for a given query. In addition, explanation of the performance indicators of the query-solving process contributes to the understanding of the resolution process. These performance indicators can be effectively used to help in formulating queries by suggesting alternative queries based on the history of the performance of the query-solving process. Another focus of this thesis is on how the distribution of the queries can be performed over the distributed sources and how explanation can be used to better understand the queries and their results over the distributed sources.
In the early stage of this thesis, our current focus is on explaining the Semantic Web query results taking the inferences into account. We are working on justification of results for SPARQL query with RDFS entailment. Our next focus will be on the different abstractions of these justifications with different degree of details and different types of presentations depending on different level of user expertise.
Pervasive Sociality through Social Objects
Participants : Nicolas Marie, Fabien Gandon.
The work is related to semantic spreading activation algorithm, from idea to first results and visualization. Spreading activation is a method for searching semantic networks by labeling a set of initial nodes with weights (called activation), propagating (spreading) that activation out to other nodes linked to the source nodes and iterating propagation. Previously, at the end of 2010, we designed an ontology called OCSO (http://ns.inria.fr/ocso/V0.2/ ). This ontology aims at describing in a structured format social objects (content augmented by social functionalities independently of its nature: video, place, text, etc.) and corresponding social activity. Then, the need of powerful and semantic sensitive algorithm to process such data led us to follow the track of semantic spreading activation.
Two posters were published at IC [42] and Web Science [43] presenting OCSO model and research axis about semantic spreading activation. A state of the art about exploitation of semantics in spreading activation and its position in the general context of this algorithm family was written. Then a formal proposition was made and algorithm development started leading to first experimental results. The state of the art, the formal proposition and early results were published at the Social Objects workshop [41] . The end of the year was mainly focused about results visualization through Gephi and knowledge acquisition on algorithm and its behavior through multiple tests.